
こんにちは。ツバサです。家計簿のカード連携を自力でやってみようの第2回です。
前回、seleniumを使って楽天カードの明細(csv)をダウンロードしました。

前回のプログラムで、昨日時点の明細と今日時点の明細が作成されます。
今回はこの2つのcsvファイルを比較して、新たに増えたデータの抽出を行います。
この抽出されたデータが、家計簿へ新規登録しないといけないデータです。
また、このプロジェクトの全体像についてはPart0に書いています。ぜひこちらもご覧ください↓
フローとソースコード
結論として、フローとソースコードを記載します。
フロー
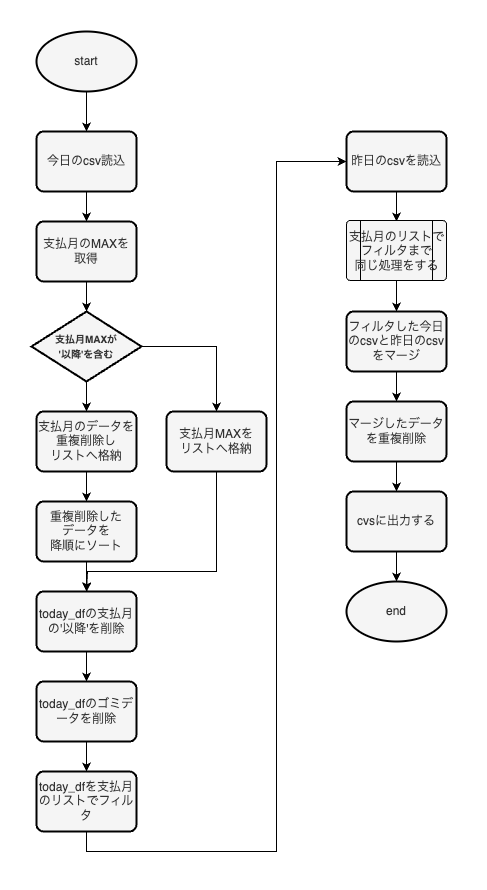
このフローをざっくり説明します。
まずは現在の日付から支払月を計算します。支払月は来月です。例えば、今が6月だとすると支払月は7月になります。
次に、前回の記事でDLした今日時点のcsvファイル(today.csv)をpandasで読み込んでデータを整形します。
同様に、昨日時点のcsvファイルにもデータ整形します。
整形できた2つのデータを合体し、重複しているデータを削除します。これによって新たに増えた支払データの抽出が完了です。
↑の説明は最後の注意点とかでまとめられるのでは?
ソースコード
import pandas as pd
from datetime import datetime,timedelta
from dateutil.relativedelta import relativedelta #来月を出す
import re
import numpy as np
# 今日のcsv読み込み
today_df = pd.read_csv('./today.csv')
#支払月のリスト作成する
pay_month = []
max_paymonth = today_df['支払月'].max() # dataframeの「支払月」列で最大の値を取る
if('以降' in max_paymonth):
_pay_month = np.sort(today_df['支払月'].unique())[::-1] # 降順でソート
pay_month = [m.replace('以降', '') for m in _pay_month] # '以降'を削除
else:
pay_month.append(max_paymonth)
# 今日のcsvデータ整形
today_df['支払月'] = today_df['支払月'].replace(re.compile(r'以降$'),'',regex=True) # 明細の「支払月」にある'以降'を削除
_today_df = today_df.rename(columns = {today_df.columns[0]:'利用日'}) #「利用日」のヘッダに不要なダブルクォーテーションがあるのでこれを消す
_today_df = _today_df[_today_df['利用日'].notnull()] # ETCの利用データは2つできる(1個は利用店名・商品名にしか値がないゴミ)。これを消す
filtered_today = _today_df[_today_df['支払月'].isin(pay_month)] # 今日のcsvから対象の支払月のデータだけ抜き出す
# 昨日のcsv読み込み
yesterday_df = pd.read_csv('./yesterday.csv')
# 昨日のcsvデータ整形
yesterday_df['支払月'] = yesterday_df['支払月'].replace(re.compile(r'以降$'),'',regex=True) # 明細の「支払月」にある'以降'を削除
_yesterday_df = yesterday_df.rename(columns={yesterday_df.columns[0]:'利用日'}) #「利用日」のヘッダに不要なダブルクォーテーションがあるのでこれを消す
_yesterday_df = _yesterday_df[_yesterday_df['利用日'].notnull()] # ETCの利用データは2つできる(1個は利用店名・商品名にしか値がないゴミ)。これを消す
filtered_yesterday = _yesterday_df[yesterday_df['支払月'].isin(pay_month)] # 昨日のcsvから対象の支払月のデータだけ抜き出す
# 今日と昨日のデータをマージ
merged_df = pd.concat([filtered_yesterday,filtered_today])
_merged_df = merged_df.rename(columns={merged_df.columns[0]:'利用日'})
# 重複削除後のdataframeを用意
diff_df = pd.DataFrame(index=[],columns=filtered_today.columns)
# 必要なカラムだけで重複削除
diff_df = _merged_df.drop_duplicates(keep=False,subset=['利用日','利用店名・商品名','利用者','支払方法','利用金額'])
# 結果を出力する
diff_df.to_csv('./diff.csv', index=False)データの内容
楽天カードの利用明細のイメージです。
| 利用日 | 利用店名・ 商品名 | 利用者 | 支払方法 | 利用金額 | 支払手数料 | 支払総額 | 支払月 | 7月支払金額 | 8月繰越金額 | 8月以降支払金額 |
|---|---|---|---|---|---|---|---|---|---|---|
| 2023/06/10 | 食料品 | 本人 | 1回払い | 1,000 | 0 | 1,000 | 7月 | 1,000 | 0 | 0 |
ヘッダの後ろ3列は、現在の日付によって変わります。上の例では、現在が6月の場合です。
7月になると、”8月支払金額”,”9月繰越金額”,”9月以降支払金額”と1ヶ月ズレていきます。
このデータの中で、家計簿の特録に必要な情報は4つです。
- 利用日
→ 支払った日。家計簿の「日付」へする。 - 利用店名・商品名
→ 購入したお店や商品名。家計簿の「品目名」へ入力する。 - 利用金額
→ 購入にかかった金額。家計簿の「金額」へ入力する - 支払月
→ カードの引き落としが起こる月。家計簿へ新規登録が必要なデータの抽出に使用。
データ整形について
データ整形を行う理由は、重複削除を正しく行えるようにするためです。
重複削除がうまく行えない原因は下記3点です。
- 月次が変わったタイミング
- ETCのゴミデータとヘッダの文字化け
1. 金額が確定する前後
楽天カードの利用金額は、毎月12日に確定します。
確定前の利用明細は下記のように、今月引き落としの明細と来月以降に引き落としの明細が混合します。
| 利用日 | 利用店名・ 商品名 | 利用者 | 支払方法 | 利用金額 | 支払手数料 | 支払総額 | 支払月 | 7月支払金額 | 8月繰越金額 | 8月以降支払金額 |
|---|---|---|---|---|---|---|---|---|---|---|
| 2023/06/10 | 食料品 | 本人 | 1回払い | 1,000 | 0 | 1,000 | 7月 | 1,000 | 0 | 0 |
| 2023/07/05 | AMAZON | 本人 | 1回払い | 3,000 | 0 | 3,000 | 8月以降 | 0 | 0 | 3,000 |
| 2023/05/07 | ETC | ETC | 1回払い | 2,500 | 0 | 2,500 | 7月 | |||
確定後は、下記のように来月以降に引き落としの明細のみが残ります。そして、支払月にあった「以降」の文字が消えます。
| 利用日 | 利用店名・ 商品名 | 利用者 | 支払方法 | 利用金額 | 支払手数料 | 支払総額 | 支払月 | 8月支払金額 | 9月繰越金額 | 9月以降支払金額 |
|---|---|---|---|---|---|---|---|---|---|---|
| 2023/07/05 | AMAZON | 本人 | 1回払い | 3,000 | 0 | 3,000 | 8月 | 0 | 0 | 3,000 |
これの何が問題かというと、確定前後の明細で差分を取ると支払月=7月の明細も差分として出てきてしまうことです。
対策としては、支払月に”以降”を含むデータがあった時は明細にある全ての支払月を対象に差分を取ります。
そうでない場合は、最大の支払月を対象にします。
2. ETCのゴミデータとヘッダの文字化け
ETCの利用情報は、「利用店名・商品名」以外が空白のゴミデータが一緒にできます。(理由は謎です・・・)
| 利用日 | 利用店名・ 商品名 | 利用者 | 支払方法 | 利用金額 | 支払手数料 | 支払総額 | 支払月 | n月支払金額 | n+1月繰越金額 | n+1月以降支払金額 |
|---|---|---|---|---|---|---|---|---|---|---|
| 2023/06/10 | 食料品 | 本人 | 1回払い | 1,000 | 0 | 1,000 | 7月 | 1,000 | 0 | 0 |
| 2023/07/05 | AMAZON | 本人 | 1回払い | 3,000 | 0 | 3,000 | 8月以降 | 0 | 0 | 3,000 |
| 2023/05/07 | ETC | ETC | 1回払い | 2,500 | 0 | 2,500 | 7月 | 0 | 0 | 0 |
| ETC |
このゴミデータを除去しないと、対象の支払月でフィルタをかけるときにエラーが出ます。
そこでpandasを使って利用日 = nullのデータを弾くことで、ゴミデータを削除します。
利用明細のcsvにはさらに問題があります。
それは、ダウンロードしたcsvのヘッダは「利用日」だけ文字化けしており、dataframeのカラムの指定がうまくできませんでした。
↓のような感じで、”?””利用日”””というデータになっています。

文字化けするのは、requestでDLした時に何かしら原因がありそうですが、ここで修正することにしました。
csv読み込みから、ゴミデータ削除までのコードがこんな感じです。
today_df = pd.read_csv('./today.csv') # csv読み込み
today_df['支払月'] = today_df['支払月'].replace(re.compile(r'以降$'),'',regex=True) #以降を削除
_today_df = today_df.rename(columns = {today_df.columns[0]:'利用日'}) #「利用日」のヘッダを修正
_today_df = _today_df[_today_df['利用日'].notnull()] # ゴミデータ削除まとめ
データ整形のところは、月に1回しかデバッグのチャンスがないのでプログラムの修正が大変でした。
しかも、問題点は1回で全て出てきてくれないので・・・
最後までご覧いただき、ありがとうございました。
次回はこの重複削除した明細を食費や交際費などのカテゴリへ分類します。


コメント